
过采样在数据平衡中的重要性与方法解析
在现代数据科学的世界中,数据不平衡问题如同一颗隐形炸弹,随时可能引发模型性能的崩溃。为了有效应对这一挑战,过采样技术应运而生。本文将深入探讨过采样在数据平衡中的重要性及其常用方法,力求让您在轻松幽默的氛围中,掌握这些关键概念。
什么是过采样?
过采样是一种数据预处理技术,主要用于解决类别不平衡的问题。在分类任务中,如果某一类样本数量远远少于其他类别,模型在训练时可能会偏向于多数类,导致少数类的预测性能大幅下降。因此,过采样通过增加少数类样本的数量,帮助模型更好地学习到各类的特征。
过采样的基本原理
过采样的核心在于“增加”少数类样本。常见方法包括:
1. 复制现有样本:简单粗暴,但效率低下。
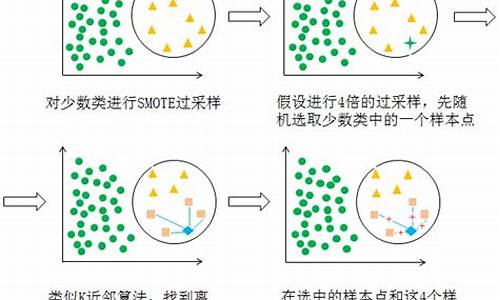
2. 生成合成样本:使用技术如SMOTE(合成少数类过采样技术),通过插值来生成新样本。
3. 数据增强:通过旋转、缩放等手段增加样本多样性。
过采样的重要性
为什么要重视过采样?答案很简单——它可以显著提升模型的准确性和泛化能力。
提升模型性能
通过平衡数据集,模型能更全面地学习不同类别的特征,从而提高对少数类的识别率。想象一下,如果你只听过一首歌,你能否准确评价整个音乐专辑?显然,过采样就是为你的数据“调音”。
降低偏倚风险
不平衡的数据集容易导致模型产生偏倚,过采样则相当于给模型上了一层保护膜,让它在决策时更加公正。
常用的过采样方法
过采样的方法多种多样,各自有其独特的优势和适用场景。
随机过采样
这种方法最为简单,通过随机复制少数类样本来达到平衡。但需谨慎使用,因为可能导致过拟合。
SMOTE技术
SMOTE(Synthetic Minority Over-sampling Technique)是一种智能生成合成样本的方法。它通过找到少数类样本之间的距离,生成新的样本点,使得数据分布更加合理。
ADASYN方法
ADASYN(Adaptive Synthetic Sampling)类似于SMOTE,但更注重困难样本的生成。它通过分析样本的分布情况,自适应地生成样本,使得模型在难以预测的区域也能获得更多经验。
过采样的注意事项
虽然过采样能够显著提升模型的表现,但在使用时也需注意。
过拟合风险
过多的重复样本可能导致模型记住训练数据,而无法在新数据上保持良好的表现。适度过采样尤为重要。
计算成本
某些过采样方法,如SMOTE,可能需要较长的计算时间和资源,应根据实际需求选择合适的方法。
总结归纳
过采样作为一种有效的数据平衡技术,不仅提高了模型的准确性,还降低了偏倚风险。通过灵活运用各种过采样方法,数据科学家可以更好地应对不平衡问题,构建出更强大的分类模型。无论是在学术研究还是商业应用中,掌握过采样的技巧,将为您的数据分析之路提供强大的助力。希望这篇文章为您提供了启发,助您在数据科学的海洋中乘风破浪!